Design and review on applying the neural network to the abandoned bike report system
Abstract:
Bibliography/Citations:
Additional Project Information
Research Plan:
I. Research equipment and device
- Two mobile phones: Test the chatbot.
- Two computers: They are used for programming, writing reports, and doing experiments.
- Jupiter Notebook: It is an environment for developing the neural network learning script.
- Keras + Tensorflow: It is a neural network platform. Even beginners can use AI.
- Facebook Developer: Set up a fan page and the chatbot link.
- AWS: It is used to store all the programs and databases created in this study and it provides a 24-hour reporting service.
- Google Cloud Vision API: It is a powerful image identification engine. The user can mark specific objects in the photo. It can identify texts. This research is used to analyze images and acquire their output for AI applications.
- Google Maps API: It is a geographical information platform. In this research, it is used to find a complete address based on a partial address.
II. Background and relevant theory
(I) Process and bottleneck for handling the abandoned bike
Biking has been popular in Taiwan for the past two decades. Throughout time, there have been more abandoned bikes on the street. In Taipei, the cleaning squadron recycled 6,000 bikes in 2003, 8,264 bikes in 2012, 12,173 bikes in 2015, 11,500 bikes in 2017, and over 15,000 bikes in 2018.
The cleaning squadron works hard, but many abandoned bikes still occupy the rack and block the sidewalk. The city street looks messy. They hinder pedestrian safety because they are not recycled properly.
Recycling abandoned bikes mostly rely on patrol by the cleaner and reports by people. However, it’s not the main job of the cleaning squadron and there are not enough people for recycling. Cleaners can only check if there’s an abandoned bike while collecting trash. Therefore, there are lots of blind spots.
After someone reports the bike, the cleaner will go check the spot in a few days. If the abandoned bike meets the requirement, the cleaner will attach an announcement for recycling on the seat. The cleaning squadron will come back seven days later. If the owner did not remove the post, the cleaning squadron will take it to the disposal area and post it on the website for a month. The owner can collect it within a month. If no one collects the bike after a month, the bike will be handled at the disposal area. If the bike can be repaired, an auction will be held. If it cannot be repaired, the usable parts will be removed to repair other bikes. The rest of the parts will be recycled by the material.
The problem now is that not many people would report the bike. The main reason is that the reporting procedure is inconvenient. Many people don’t know that they can report the bike. That is why we use AI to create a Facebook chatbot as the bike reporting system.
(II) AI theory
Wikipedia states that Artificial Intelligence (AI) is also known as machine intelligence. It means the intelligence of the machine created by humans. The most important part of intelligence is learning. The machine is able to learn with the help of AI. We call it machine learning. To achieve artificial intelligence, the popular method nowadays is neural networks. It is a computing model simulating a human’s cranial nerve structure. It aims to help the computer simulate how human thinks to solve abstract problems. When using the neural network for machine learning, people developed numerous network models. Nowadays, the mainstream consensus is that there should be multiple layers in these networks, which means there should be at least one hidden layer between the input and output layers. It is called deep learning. In 2006, Geoffery Hinton proposed deep learning (multilayer neural network). This idea performed well in 2012 ImageNet.
Now there are three basic models for deep learning, Multi-layer Perceptron (MLP), Convolutional Neural Network (CNN), and Recurrent Neural Network (RNN). These are explained briefly below:
(1) Multi-layer Perceptron (MLP)
MLP is a classic neural network. It consists of one or multiple neurons. The data is sent to the input layer and stored in one or multiple hidden layers. A prediction is made on the output layer. MLP is very flexible and can be especially used for classifying and predicting problems.
(2) Convolutional Neural Network (CNN)
CNN is different from MLP. It divides numerous input neurons into several sections. Each section handles a small part of the information. These sections integrate the learning results and enter the next layer for learning. This effectively reduces complexity and does not omit important information. Many famous AI systems, e.g. Google Cloud Vision, Alpha Go, have made breakthroughs because they are based on the CNN model.
Through partial connection and shared weights and biases, CNN significantly reduces the number of parameters. Now CNN has achieved exciting achievements in numerous computer vision tasks, such as image identification, target detection, and facial recognition.
(3) Recurrent Neural Network (RNN)
Compared to MLP and CNN, RNN uses shared weights and biases to handle the extended sequence. (The fully connected layer needs the input from the fixed dimension, CNN can only accept input from the fixed dimension.) RNN introduced a ring structure. The input at a certain time is associated with the concurrent input and the status at the previous time. Through shared weights and biases, RNN is especially suitable for learning signals with timelines, such as translation, text mining, chatbot, voice recognition...etc.
The number of hidden nodes is a critical parameter of MLP. The neural network with too many nodes might overfit data. Its generality for the data not used for the training is poor. The number of hidden units configured under the model is low. The neural network is not quite accurate. This issue deeply troubles scientists. Therefore, they brought up aspects from different perspectives. Jason Brownlee suggested using the following five methods to find the solution, experiment, intuition, prioritized depth, literature review, and case search. Foram thought that no specific method could predict the number of layers of neurons required. He organized several common suggestions, such as that the number of neurons on the hidden layer should be on the same quantity level as the output and input layers.
Based on other literature reviews and some of our small experiments, there is no solution for the number of hidden layers and the number of neurons on each layer in the MLP model. The relationship between the output and input layers is changeable. To be extreme, if the data provided for the input layer and the expected answer expected by the output layer are random and unrelated, learning is impossible regardless of the number of layers of neurons.
(III) Method and process
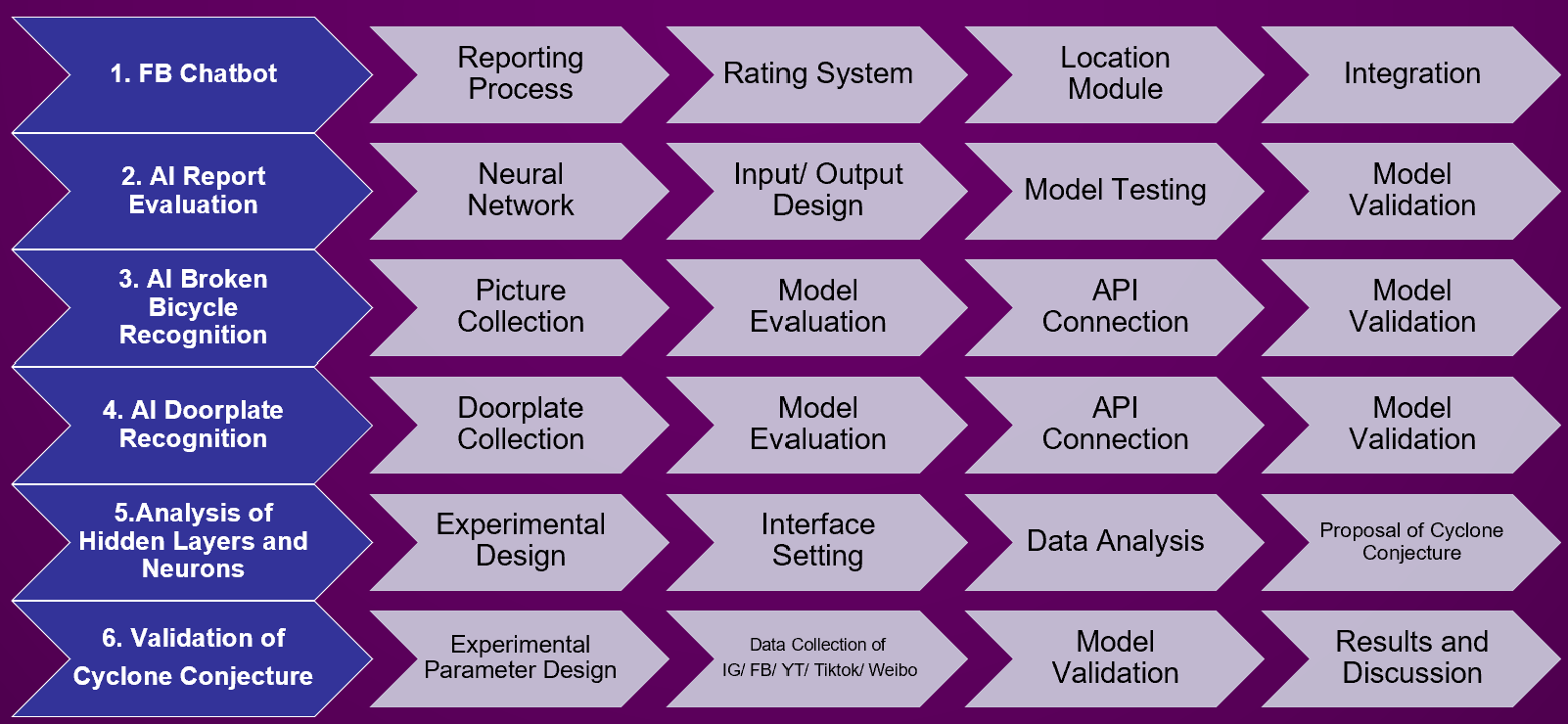
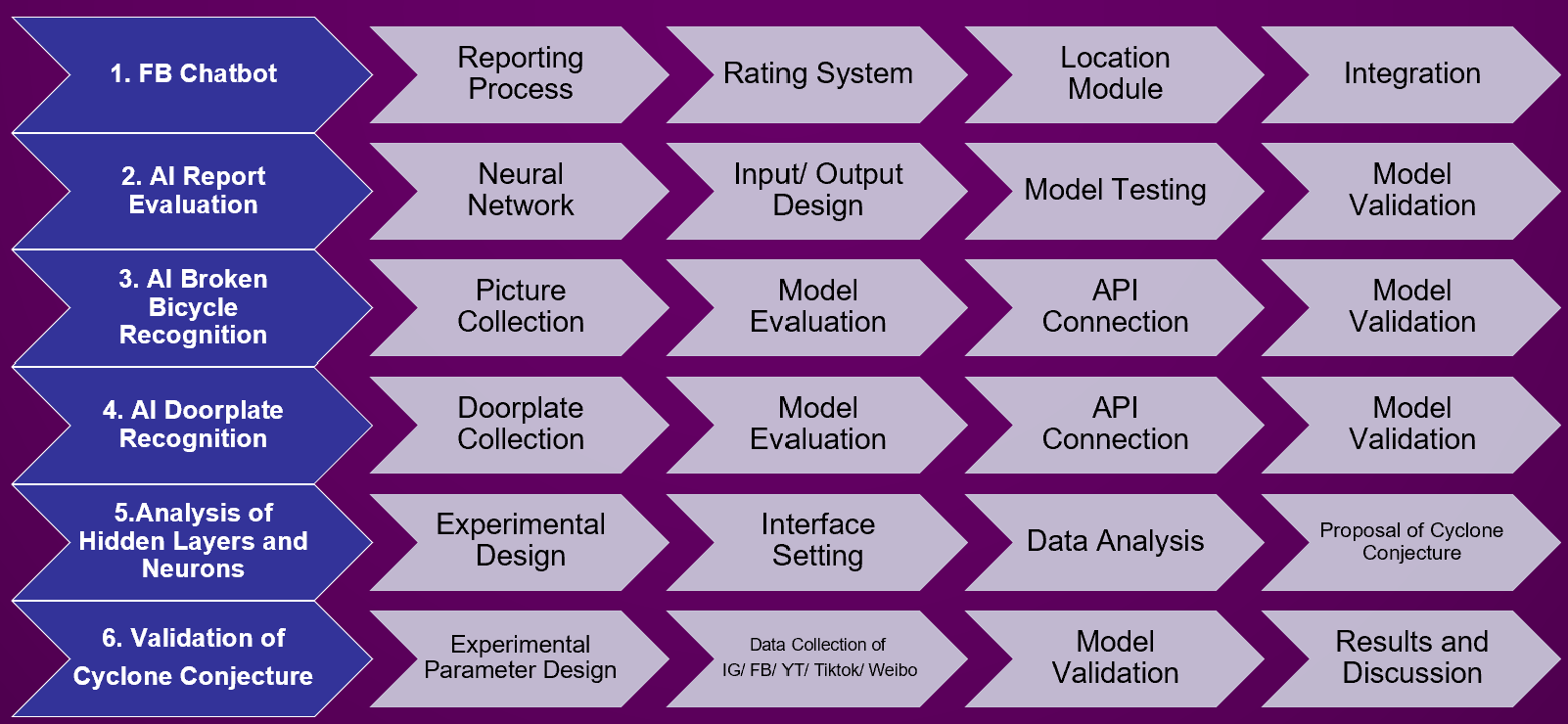
According to the study purpose, this study can be divided into five parts:
1. Facebook chatbot
2. AI post rating
3. Bike image recognition
4. Address analysis based on house number
5. Study on the number of hidden neurons
Based on the five parts above, the following diagram shows the study method and process:
Questions and Answers
- What was the major objective of your project and what was your plan to achieve it?
- There is a problem that AI programmers all over the world have not yet solved and debated: how many hidden layers are needed for in-depth learning, how to design the structure is the best, which is still uncertain, or whether it needs the constant attempt, error and intuition of AI training masters. On the other side, when I saw the abandoned bicycles being discarded in the streets and on the campus, I designed an AI Chatbot to solve this problem. In the process of writing the Chatbot programming language, I saw that this kind of AI learning had the best number of hidden layers, and I also confirmed it with the likes of the other five social medias, and put forward the CYCLONE hypothesis, I hope to make some contributions to the field that related to Chatbot AI programming.
- Based on these study objectives, I want to achieve the following in this study:
- 1. Make a Facebook Messenger chatbot for people to report the bike conveniently anytime.
-
2. Create an AI system to rate the reported case accurately. The cleaning squadron can recycle the bike based on the rating.
3. Use AI to identify if there is an abandoned bike in the photo.
4. Use AI to analyze and identify an accurate and complete address and house number based on the doorplate in Taiwan.
5. In the study, explore the way to determine the number of neurons in the hidden layer of MLP. Try to find a solution for unsolved issues in AI deep learning.
- Was that goal the result of any specific situation, experience, or problem you encountered?
- With bicycles being the main transportation for college students, once they graduate, a lot of them leave their bicycles on the road. The biggest problem with this is that not only our roads are blocked constantly by a plethora of bicycles, but the rust on the bicycles can also fester bacteria. The current system for recycling bicycles is also extremely ineffective, so in hopes of
- Were you trying to solve a problem, answer a question, or test a hypothesis?
- Abandoned bicycle is a worldwide problem especially in big cities and campuses. In New York, in five years, there were almost 6000 complaints relating to orphaned bicycles, and about 21%, led to the removal of the bikes. There are so many abandoned bicycles, The City of Hoboken was holding an online auction of "abandoned" bicycles. Just last month, The UC Davis estimates there are 3,000 bicycles abandoned in campus, and an additional 2,000 being held in storage facilities. But now, our AI chatbot, Cyclone, he might be the solution. We found several problems with the current reporting system: reporting a case requires manual inspection before it is sent to cleaning team members, which is too labor-intensive, and reporters cannot get feedback immediately, affecting the willingness to continue reporting.
- Our solution is to create a chatbot powered by AI to make the system efficient and drive up citizen’s willingness to report. Abandoned bicycles are a big problem, cluttering the streets and wasting resources. In the past three years through the charity “Abandoned Bicycles – Rebirth”, my friends and I have successfully recycled over 700 bicycles. Throughout the process, we found several flaws with the current system for reporting abandoned bicycles. The reporting system of every city is different, the report cannot be processed immediately, and the report requires manual review, which wastes a lot of time and manpower, and discourages citizens from reporting abandoned bicycles due to the hassle.
- Therefore, this App aims to combine artificial intelligence and our reporting system to implement in a chatbot so that citizens can file reports by simply providing the address and a photo of the bicycle. Then the artificial intelligence system will gauge the validity of the report without manual oversight to increase efficiency.
- What were the major tasks you had to perform in order to complete your project?
- What is new or novel about your project?
- Is there some aspect of your project's objective, or how you achieved it that you haven't done before?
- One thing that I did that was new was finding the optimal number of hidden layers that is needed to verify the correctness of the report. I found that in verifying reports with 7 neurons and 11 outputs, 2-4 hidden layers is the best to process the information.
- Using a system to report abandoned bicycles is also not yet seen.
- Is your project's objective, or the way you implemented it, different from anything you have seen?
- There has not been a system to automatically upload abandoned bicycles in messenger or anywhere
- If you believe your work to be unique in some way, what research have you done to confirm that it is?
- There is no research done on the optimal number of hidden layers to use to get not only the most accurate results, but also to process the information the fastest.
- What was the most challenging part of completing your project?
- What problems did you encounter, and how did you overcome them?
- It is necessary to build a database to record each user's status and bike reports. We choose dynamodb provided by Amazon to be our database. However, it's another challenge to understand the usage of all APIs. We planned out our chat bit flow chart and decided to use Facebook messenger as the host for our chatbot because it is easy to use and very common. So, we turned our plan into a functioning chatbot using python, then we hosted the code on an Amazon Web Service server and used DynamoDB for storage of data on the cloud.
- When it comes to image recognition, Google Cloud API is powerful, but it cost a great of time to build the entire recognition system. This study used around 500+ photos from the web and the streets to train the model. Use Google Cloud Vision API, which uses CNN neural network. The API identifies parts of the bicycle and we take the probability of individual parts such as bicycle wheel and frame determined by the API as input neurons for our AI broken bicycle recognition software. We trained the model using a 10x40x40x11 neural network but could only get about 60% accuracy. However, we have found a way to improve this accuracy. Using Auto ML could effectively obtain 92.86% accuracy. The schematic below demonstrates the result.
- It is also hard to decide which and how many neurons identified should I define and put into the calculation. How many outputs should I define? For the AI report chatbot evaluation, we use MLP as a model for neural networks and define 1 input as 7 neurons identifying a. Photo? (0/1) b. Abandoned Bike in Photo? (0-10) c. new User? (0/1) d. Past Average Score? (0-10) e. Total Previous Reports? (0-100) Reports in the last 10 minutes? (0-100) h. Is the location appropriate? (0/1). Output as 11 neurons, representing 0-10 score (10 is most credible). Which neuron has the highest probability is taken as the answer. After looking at literature and our own testing, we concluded to set batch_size as 40, set each experiment to go through 500-2000 epochs, and set training to testing data ratio to 80:20. We were able to get to 99% accuracy, but we wondered if we could go further than that.
- What did you learn from overcoming these problems?
- I learned that it is important to chose a good parameter while setting the number of neurons and layers to get an optimal result.
- If you were going to do this project again, are there any things you would do differently the next time?
- Next time I hope that I can use even more data sets to increase the accuray of my project to 100%.
- Did working on this project give you any ideas for other projects?
- Analysis of of hidden layers and neurons: try to find if there’s a useful theory or presupposition behind it. I use TensorFlow to set up my neural network. Test 0 to 5 hidden layers respectively. Each hidden layer starts from 10 neurons and gradually increases the number of neurons (10, 20, 40, 80 ...) until there is no more change. After finishing the App, I conduct 27 experiments with different conditions of number of hidden layers and the number of neurons per hidden layer. Every experiment will generate complete data including computational weight, accuracy graphs, loss graphs, and errors during training, etc. I highlight the first experiment to reach 99% accuracy in each # of hidden layers category. By observing patterns throughout the entire study and especially looking at these highlighted experiments, I was able to obtain the conclusion that having 2-4 hidden layers and 1-10x the average between the number of input and output neurons per layer is an optimal configuration for both efficiency and accuracy. I called the experimental model Cyclone Conjecture and utilized this model in other cases (5 popular social media) to verify our idea. In order to verify the model of Cyclone Conjecture we proposed, I prepared a set of 1000 data for each social media website. 5000 data sets were prepared in total. After I apply the model to 5000 data collected from 5 social media websites, I found that with 2-4x the hidden layer and 1-10x the average between the number of input and output neurons per layer, we could obtain the highest accuracy while not compromising computational weight. From the experimental results, we observed that the Youtube result are lower than other media. Even the highest accuracy is lower than 60%. This can be attributed to the diversity of input parameters to bring out the lower accuracy.
- Also made me think if this kind of reporting system can be used on not just reporting abandoned bikes, but also report different things such as abandoned scooters, or even trash than needs to get recycled, and places that are dangerous that needs to be fixed.
- How did COVID-19 affect the completion of your project?
- As my project mostly involved coding and online work, it did not affect the completion of my project as much.